For years, engineering organizations were relying on post-incident reviews to identify process errors, logical flaws and eventually get better. That is now in dispute. When AI generated code fails in production ownership becomes unclear. Even if the development chain looks intact, responsibility diffuses. This is more than another engineering issue. It’s a governance and business risk, and moreover most leadership teams haven’t yet realized.
I’ve been watching this emerging pattern in my organization, but also in conversations with peers running engineering teams at scale. The trend is obvious, teams adopted AI coding tools because the productivity case was obvious. The governance question got deferred, or in best case right-shifted. Now incidents are surfacing where nobody can cleanly trace the decision chain, and the post-mortems are less useful than they used to be.
The obvious objection is that the committer is responsible. Strictly speaking, that’s true. But as AI-assisted and vibe-coding cadence increases, that rule is no longer sufficient as a governance model. In real life it’s impossible to hold a single person responsible for every line generated. Everything is optimized for velocity, incentives, tooling, and review throughput, the whole engineering process is built around that. The question is not whether developers have responsibility. The question is whether organizations have the governance and systems that make responsible ownership operationally real.
This is not a technology problem. It is an organizational problem created by technology, and engineering leadership has to solve it before a court, a regulator, or a customer’s legal team does it for us.
How We Used to Know Who Owned It
The old model was not perfect, but it was legible. You knew who wrote the code because their name was on the commit. You knew who approved it because someone had to click merge. When something failed, you could walk back the chain. Post-incident reviews were useful because there was a real sequence of human decisions to examine. There were processes to review and improve, and the organization got better over time because of it.
That’s what accountability has always been in engineering organizations. Not a mechanism to blame, but a way to get better. Teams that could point to a specific decision or gap could understand why it was made and how to improve the process that led to it. That accountability chain was the spine of reliability engineering long before we called it that.
This model assumed one thing: that a human being made every material decision in the code’s path from idea to production.
For thirty years, that assumption held. It doesn’t anymore.
The Click That Dissolved Accountability
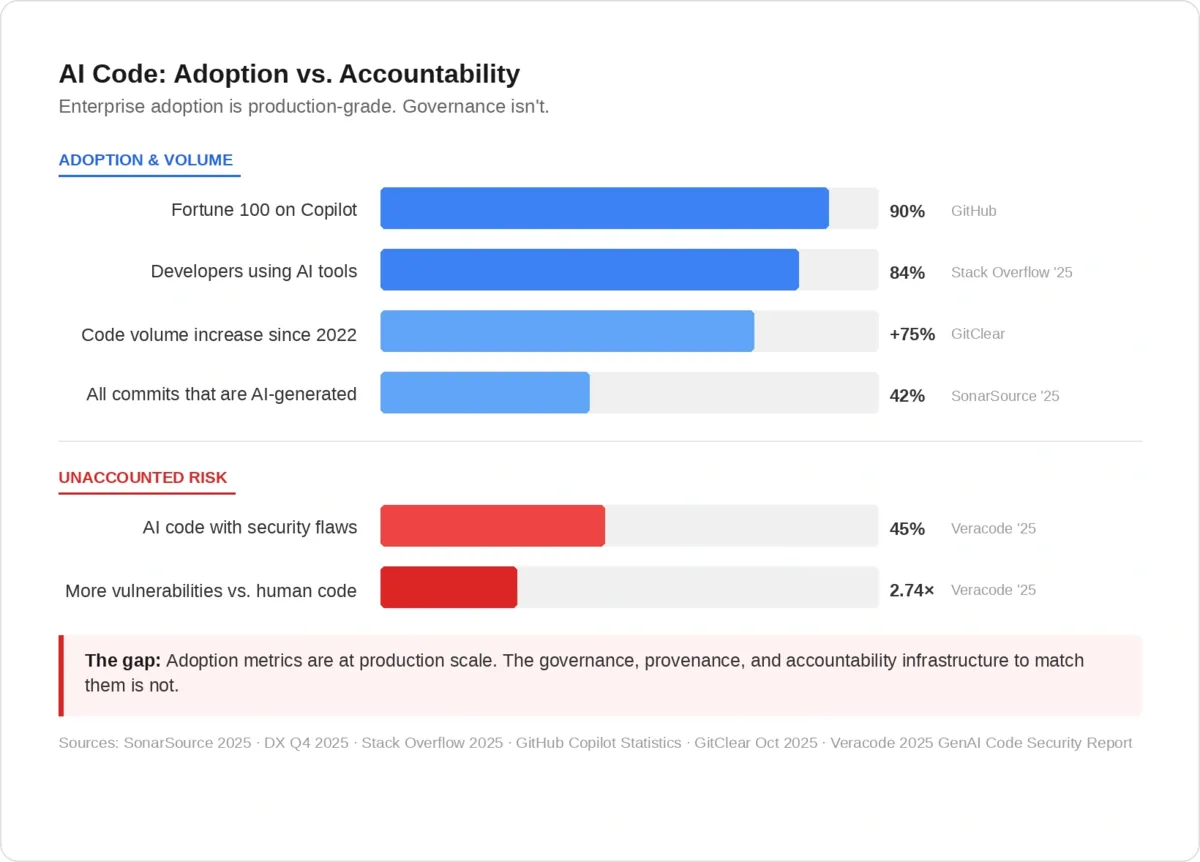
The numbers tell the story well enough. SonarSource’s 2025 data puts AI-generated or assisted code at 42% of all commits. DX’s Q4 2025 report , analyzing over 135,000 developers they found 22% of merged code is AI-authored. The 2025 Stack Overflow Developer Survey has 84% of developers using or planning to use AI tools, more than half of them daily. GitHub reports 90% of Fortune 100 companies on Copilot. Not PoCs, Production.
And the volume keeps climbing. GitClear’s analysis shows developers checking in 75% more code than in 2022. Review throughput hasn’t followed. I haven’t seen an engineering organization where it has, honestly, including my own.
So here’s the thing about the “accept” click. In theory the developer reviews the suggestion, checks the edge cases, evaluates fit and then accepts. But in practice, the tools are built for speed, the incentive structures reward velocity. Some people review carefully. Many move on.
What makes this worse is that AI-generated code typically looks correct. It compiles. It follows patterns. It passes the basic tests. The failures aren’t the kind a reviewer catches in five seconds, syntax errors, missing imports, obvious typos. They’re contextual and sometimes so hidden that you need to have deep understanding of every angle of the system. A function that handles the happy path but misses a race condition your system has been carrying for two years. An API call that works fine in isolation but doesn’t respect the retry budget your service relies on under load. Clean-looking code with architectural flaws that only show up when something else goes wrong. By then, good luck tracing it back to the suggestion that caused it.
The click has become a legal and organizational fiction, a gesture that implies review without guaranteeing it. It’s what happens when tools move fast and governance doesn’t follow.
Every major coding assistant ships with some variation of “AI can make mistakes. Verify the output.” That line isn’t for the developer. It’s for the provider’s legal team. It says, quite precisely: we generate, you own. Read it that way once and you can’t unread it.
Makes sense from the vendor side. Makes considerably less sense from the deploying organization’s side, which is where most of us live. That disclaimer pushes the risk downstream. Downstream is you.
The Legal System Is Catching Up Before Organizations
The most important case of law is Mobley v. Workday.1 In July 2024 a USA federal judge allowed a hiring discrimination case to proceed against an AI vendor. Based on hypothesis that Workday’s AI screening tool was acting as an agent of the employer. In May 2025 the court granted preliminary collective certification. The number that came out of that filing: 1.1 billion job applications routed through the system.
The direction that judge took is what matters here. The Agency theory, applied to AI. Meaning when a system takes consequential actions, the parties who deployed it and the parties who built it can both be held liable, the same way an employer is responsible for an employee’s conduct on the job. The disclaimer it’s a trail marker pointing lawyers your way.
Courts (in US at least) so far haven’t settled precedent on AI-generated code specifically. But the direction is clear, and anyone who has worked on enterprise leadership, legal, IT or procurement in the last eighteen months can feel where it’s going. Liability flows to the organization that deployed the tool. The tool provider’s disclaimer is the beginning of the conversation, not the end of it.
The EU AI Act reinforces this for European-facing products.2 Audit trails. Risk management documentation. Evidence of governance. The architecture either produces this evidence cleanly or it doesn’t, and under audit pressure is a terrible time to discover which one you built.
Building the Accountability Layer
I should be direct, this is not a case against AI adoption. The efficiency gains are real and in many cases substantial. I’ve been working through the same questions for some time now, figuring out how to move faster and more safely at the same time across multiple product lines. Slowing down isn’t the answer. Having no governance while you accelerate isn’t either. The most engineering leaders I know, are all wrestling with some version of this.
What I’m arguing for is the infrastructure that makes fast adoption sustainable. Four things, specifically.
Provenance. Which code was AI-generated. Which tool produced it. Who accepted it. When. If you can’t answer those four questions during a post-incident review, you’ve got a governance gap and you don’t know how deep it goes yet. Everything else here depends on getting this right first. Every AI-assisted change should carry traceability by design, not to satisfy auditors, but to reconstruct decisions when systems fail.
Differentiated review. AI-generated code doesn’t fail the way human code fails. Different patterns, different risk profile. Veracode’s 2025 GenAI Code Security Report found 45% of AI-generated code carries security flaws, 2.74 times more vulnerabilities than human-written code across the languages they tested. That’s a significant number. The role of human review shifts here. It becomes less about line-by-line correctness (that’s what the tooling should catch) and more about intent: does this code fit the architecture? Does it respect constraints that aren’t visible in the function signature? Most review checklists were written for human-authored code. They need updating.
Ownership clarity. Somebody, a real person, a specific team, has explicitly decided: when AI-generated code causes a production incident, here is who owns the response, here is the escalation path, here is what we tell customers. I’ve asked this question to many engineering leaders over the past year. Most haven’t made this decision yet. They will, eventually. Ideally not during the incident that forces it. The developer remains responsible for intent. The organization is responsible for the system that shapes how AI is used, enforces standards, and constrains unsafe paths. Accountability has to move from purely individual to systemic.
Audit legibility. When your legal team, a regulator, or an enterprise customer asks “show me your governance over AI-generated code,” you need an answer in hours. Not weeks. Right now most organizations need weeks. Or they give a carefully worded response that basically translates to we haven’t figured this out yet. Governance can’t be a post-incident activity. It has to live where decisions are made, at commit, in CI/CD, in code review, with measurable signals like traceability coverage, review depth, and attribution clarity.
And one more thing that doesn’t always come up, not all generated code carries the same risk. A utility function and an authentication handler are fundamentally different in what happens if they’re wrong. Part of building this infrastructure is defining trust layers, explicit distinctions in validation based on what the code touches and what breaks if it fails. Treating all AI-generated code the same, whether with blanket acceptance or blanket suspicion, means you’re doing neither well.
The Missing Layer
AI introduces a new class of decisions into the development process. Code that is generated, not authored. Accepted, not fully understood. Shipped at a speed that outpaces validation. These decisions are currently unmanaged in most organizations.
What’s missing is essentially a control plane for engineering governance, a layer that tracks decision lineage across humans and AI, enforces policy before code reaches production, and makes ownership observable instead of assumed. Without it, accountability is a retrospective exercise, something you reconstruct after an incident. With it, accountability becomes a property of the system itself.
That changes the question engineering leaders should be asking. Not “who wrote this?” but “did we design a system where ownership remains real under AI-assisted development?”
When Scale Changes the Nature of the Problem
The pillars above apply everywhere. But they become non-optional once “redeploy and move on” stops working as a recovery strategy and that threshold is lower than most organizations think.
In a multi-region SaaS platform, a governance gap in one service can cascade across regions before anyone is awake in the right timezone. The blast radius is customer data, SLA exposure, and regulatory reporting obligations that differ by jurisdiction. When the post-incident review asks “who accepted this code and what was the review process,” the answer has to be specific.
In a sovereign or compliance-bound environment, FedRAMP, SOC 2, even PCI-DSS the operational regimes that government and regulated enterprise customers require, AI-generated code with no clear provenance isn’t just a reliability problem. In FedRAMP, it’s an authorization-to-operate risk. In SOC 2, it’s a control effectiveness gap, your change management and code review evidence either demonstrate that SDLC controls are designed and operating effectively, or they don’t. Either way, auditors aren’t interested in “we’re not sure who reviewed that.” The governance evidence either exists or the certification is at risk, and rebuilding it retroactively is orders of magnitude harder than building it in.
In edge and device fleet systems cloud management planes responsible for the lifecycle of millions of deployed devices, firmware, configuration drift, policy enforcement, this expands further. There is no clean rollback. What passes for one takes days, across intermittently connected devices spanning multiple regulatory jurisdictions. Code that nobody can trace back to a review decision isn’t a security finding you patch next sprint. It’s a fleet incident.
These aren’t separate challenges. They’re the same accountability gap at different points in the architecture and I am sure there are several other. Most of us are building platforms that span more than some of these contexts, or variations. Governance has to keep pace with that reality.
Where to Start
If you’re an engineering leader reading this and wondering what to do next week, not next quarter, here’s where I’d start.
Test your provenance. Pick a recent production incident or any merged PR from the last month and try to answer four questions: was any of this AI-generated? By which tool? Who accepted it? What was the review process? If that takes more than an hour, you’ve measured the gap.
Make the ownership decision. Get legal, your CISO, and your platform or infrastructure lead in a room. Decide explicitly: when AI-generated code causes a customer-facing failure, who owns the response? Who communicates externally? What’s the escalation path? Write it down. Most organizations haven’t done this. Do it before an incident forces you to improvise it.
Assign the mandate. One team, or similar arragement, usually platform engineering is the natural fit. They own AI code governance standards. Not “everyone is responsible,” which in practice means nobody is. A named team, with authority to define quality gates, enforce provenance tracking, and update review standards as the tooling evolves.
Instrument your pipeline. Start tagging AI-generated code at commit time. It doesn’t have to be perfect on day one, even a basic annotation that distinguishes AI-assisted from human-authored gives you something to query, measure, and improve. You can’t govern what you can’t see.
None of this requires a six-month initiative. It requires a decision, a room, and the willingness to treat this as infrastructure rather than policy.
Who Needs to Be In This Conversation
Engineering can’t make this decision alone. The moment AI-generated code fails in a way that hits customers, the conversation pulls in legal, compliance, the CISO, and maybe more. If those people weren’t involved when the governance model was designed, you’ll be designing it under the worst possible conditions.
The platform engineering team is the natural owner of this infrastructure, provenance tracking, differentiated quality gates, audit tooling that makes governance legible rather than aspirational. If a platform engineering function doesn’t exist yet, this is one of the stronger arguments for building one. And at the core it’s a cross-functional question: who in the organization has the explicit mandate to define and enforce standards around AI-generated code? In most organizations I’ve engaged with recently, the honest answer is nobody, specifically. That ambiguity is exactly the gap.
What This Is Really About
Let me put a stake in the ground on something. AI coding tools are a net positive. Most AI-generated code works fine. Teams are shipping better products faster because of these tools and that trend will accelerate. We allo use them. Nothing I’ve argued here suggests we should stop.
But scale changes the nature of risk. What’s manageable when 10% of your codebase is AI-assisted looks very different at 42%. And similarly based on your Solution nature and scale can be worse. The failure modes are subtle. The accountability chain is dissolving. The legal and regulatory environment is moving, in some cases faster than the organizations it governs. Teams that build accountability architecture now, provenance, differentiated review, ownership, audit legibility, will actually adopt AI faster than their competitors. Because they’ll have the foundation to do it without accumulating governance debt they’ll eventually have to pay down under pressure.
There’s a quieter reason to care too, underneath the compliance risk and legal exposure. Accountability is how engineering organizations get better. When ownership is clear, teams learn from failure. They tighten standards. They build more reliable systems. When ownership is diffuse, the same problems repeat, usually at larger scale, usually quietly, until something breaks that’s too big to explain away. Reliability isn’t a separate discipline from accountability. It’s the outcome.
The question going into 2026 is not whether to use AI coding tools. Big portion of your code may already be AI-generated regardless of whether there’s a policy document about it. The question is whether your organization has decided, explicitly, with the right people in the room, who owns the outcome when something goes wrong. Most haven’t.
The starting point isn’t a transformation program. It’s a provenance test, an ownership decision, a mandate assigned, and a pipeline instrumented. Four moves. All achievable in weeks, not quarters.
AI didn’t break accountability. It exposed where it was never properly engineered. And if you’re in a leadership role where that’s yours to fix, the right time to start was six months ago. The second-best time is now.
For the operational specifics — three shifts, tooling criteria, and a governance control plane pattern — see Make Accountability a System Property .
Mobley v. Workday, Inc., N.D. Cal. - federal court applied agency theory to hold an AI vendor liable for discriminatory hiring outcomes. Preliminary collective certification granted May 2025. See Seyfarth Shaw analysis . ↩︎